Real-time Personalization using Embeddings for Search Ranking at Airbnb
Grbovic, Mihajlo, and Haibin Cheng. "Real-time personalization using embeddings for search ranking at airbnb." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
Listing Embeddings
总体而言,针对于用户的点击序列建模还是采用了传统的Skip-gram方式,针对于业务所做的优化是:将两次点击行为之间相距超过30min的点击分割成为两个有效点击序列。
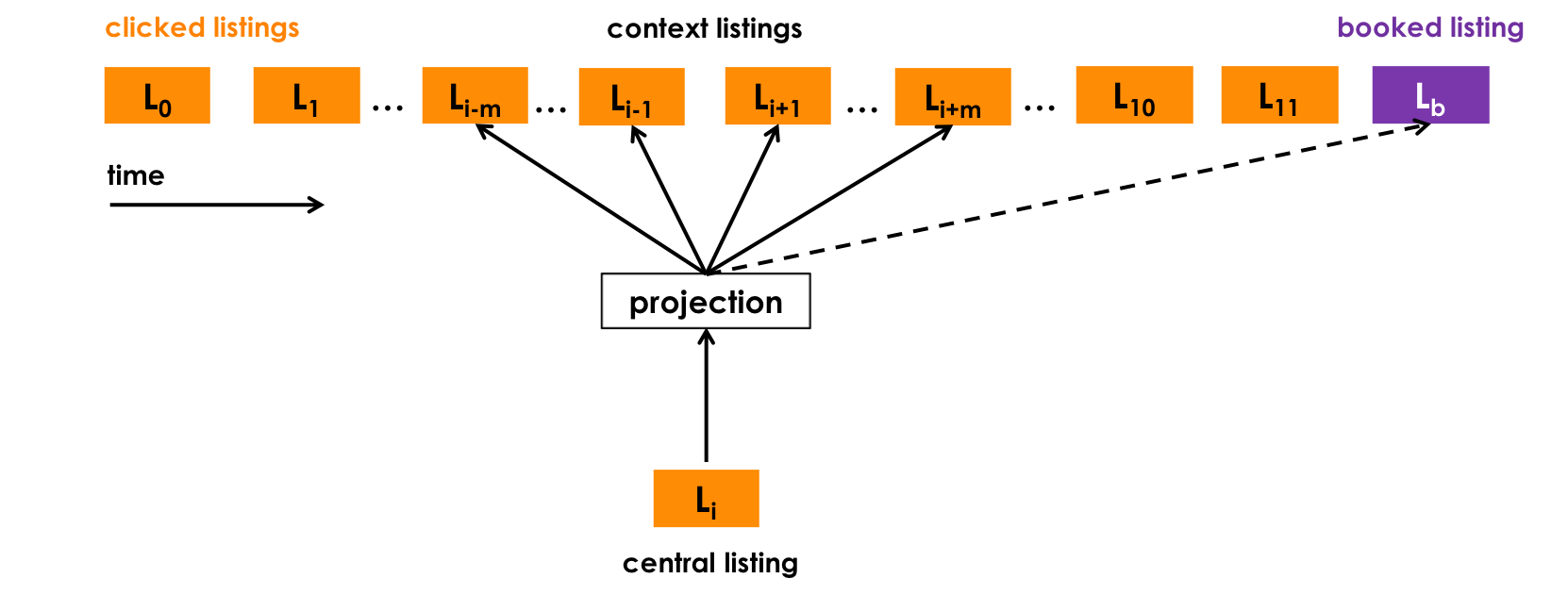
其中:
Booked Listing as Global Context
这里主要将用户点击行为分为两种:
- 预定点击:用户最终进行了购买
- 浏览点击:用户最终没有进行购买
如果是预定点击,在Skip-gram的基础上,将购买的酒店的信息在每次的训练中加入到正样本对中,损失函数就变为:
Adapting Training for Congregated Search
问题:
- 用户线上旅行的订购行为通常是基于一个比较小的样本空间范围,如:他们想要呆的地理位置区间内的样本空间范围。传统的Skip-gram中的采样得到的正样本对集合
很大概率是来自同一个样本空间范围,但是传统的Skip-gram中的负样本采样是随记采样,这就不能保证采样的负样本对集合 与正样本对集合不来自同一个样本空间范围。
解决策略
增加了一种与正样本对集合
Cold Start Listing Embeddings
对于新的房源,会存在冷启动的问题,文章中解决冷启动问题的策略为:
- 使用元数据(地理位置、价格、类型等)获得一定距离范围内具有Embedding的房源(这些房源与新房源具有相同的价格区间、类型等等)
- 然后对这些附近的房源Embedding取mean作为新房源的Embedding
Examining Listing Embeddings
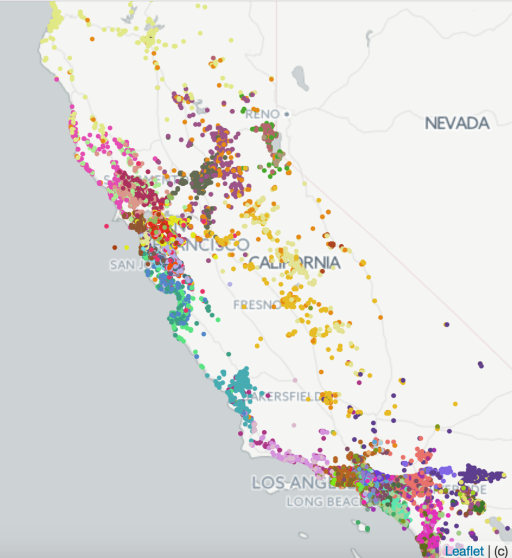
可视化Listing Embedding获取到的信息
- 通过k-means算法进行聚类操作,可以发现地理位置相同的酒店被分配到了一个簇中(California Listing Embedding Clusters)。
- 同时还评估了洛杉矶不同类型房源Embedding之间的相似度(Cosine similarities between different Listing Types)
- 洛杉矶不同类型价格区间Embedding之间的相似度(Cosine similarities between different Price Ranges)
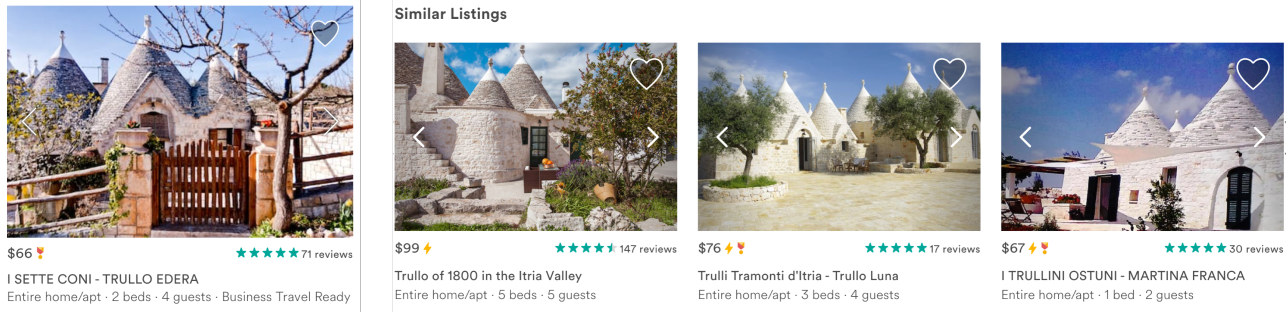
- 通过图片可视化Embedding表现不同房源的相似性(Similar Listing using Embeddings)

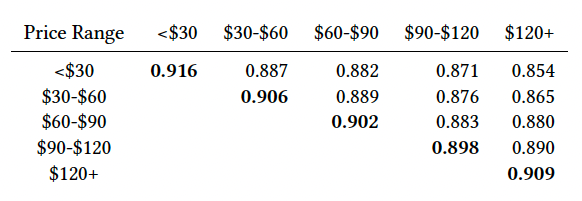
User-type & Listing-type Embeddings
问题
使用用户的订购序列数据相比于点击序列数据主要有以下难点:
- 订购行为频率远低于点击行为频率
- 许多用户订购行为序列很短,无法从中学习到足够多的潜在信息
- 从序列数据的上下文信息中学习item的embedding表征,需要该item在序列数据中至少出现5-10次,但是平台用户单个item的订购数据远远不足
- 用户的订购数据之间的时间间隔比较大,用户很可能在这段时间内的偏好发生了转变(如:职业需要或是年龄增长)
解决方法
- 学习不同type房源(用户)的embedding信息,而不是具体房源(用户)的embedding信息
- 基于某种映射关系将不同房源(用户)映射到不同的桶中
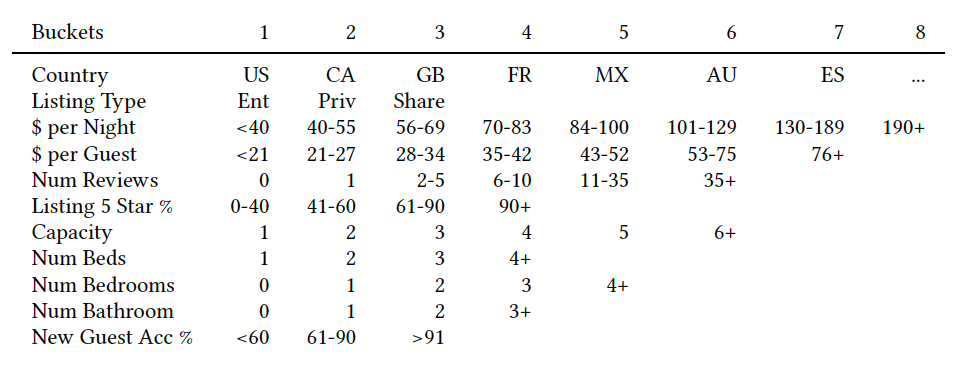
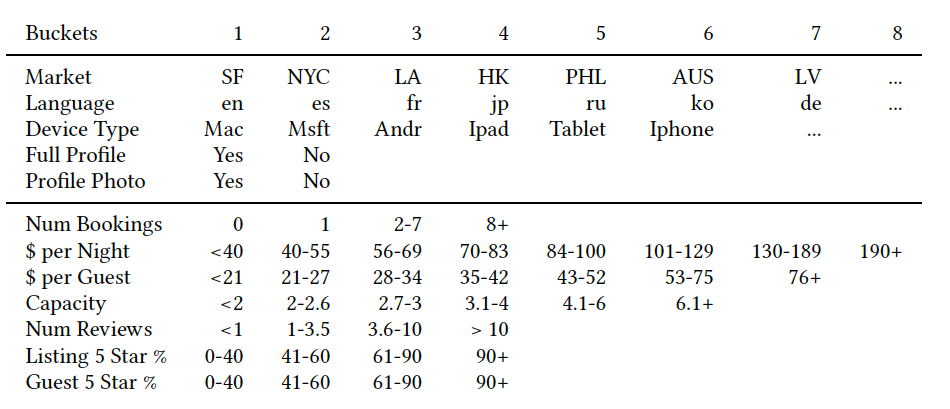
如上表所示,房源可以表中所给出的属性分到不同的桶中,例如
除此之外,针对于新用户,只需要用下表中的前5个属性进行训练,因为新用户并不含有订购行为。
Training Procedure
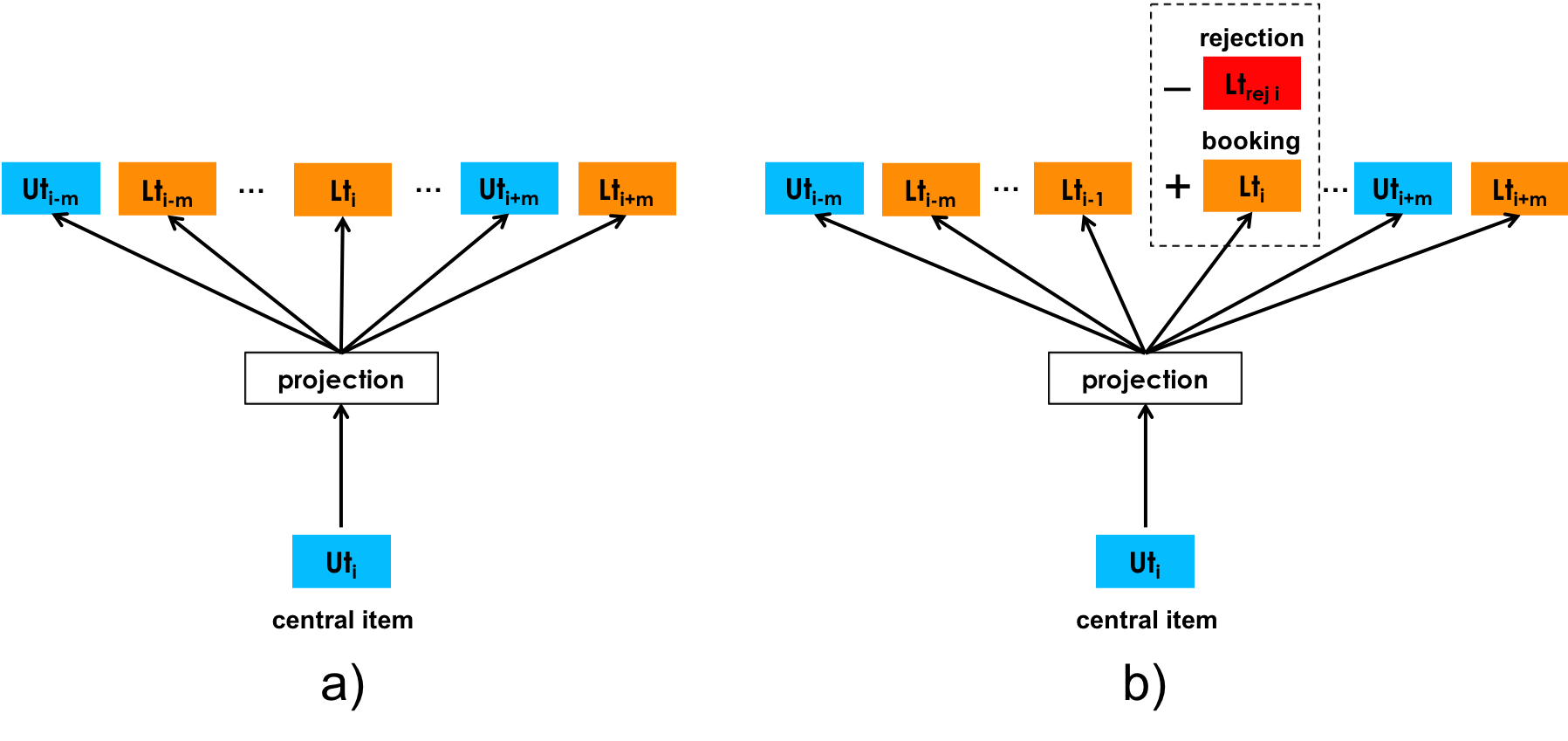
因为从用户订购数据中进行序列建模时候的负样本一定来源于不同的数据空间,所以这里不需要像从用户点击数据建模时的Adapting Training for Congregated Search策略。
Explicit Negatives for Rejections
除了Skip-gram策略中的负样本抽取策略之外,还采取了另外一种的负样本构建策略,就是如果某种类型的房源拒绝了某种类型的用户,那么对于这种用户、房源而言,与其对应的被拒绝的房源、用户可以构建成为一组负样本对。将这些负样本对也加入到损失函数的计算中。