Swing
缺点
- 未考虑用户的历史购买序列之间的关系(Swing中考虑的是i2u2i);
- 没有考虑二阶关系的衰减现象;
- 未考虑针对不同点击酒店的点击频次;
- 未融合一阶关系(Swing只针对二阶关系进行计算);
新想法
Example
Swing Recall Bad Case

但是通过分析用户点击的频率以及实时观察发现后者是更优的。用户在点击自己最终选择的酒店之前,点击了4次哈啰酒店,其频次是大于港之都酒店的点击频率的。
点击序列

Tree2I
数学建模
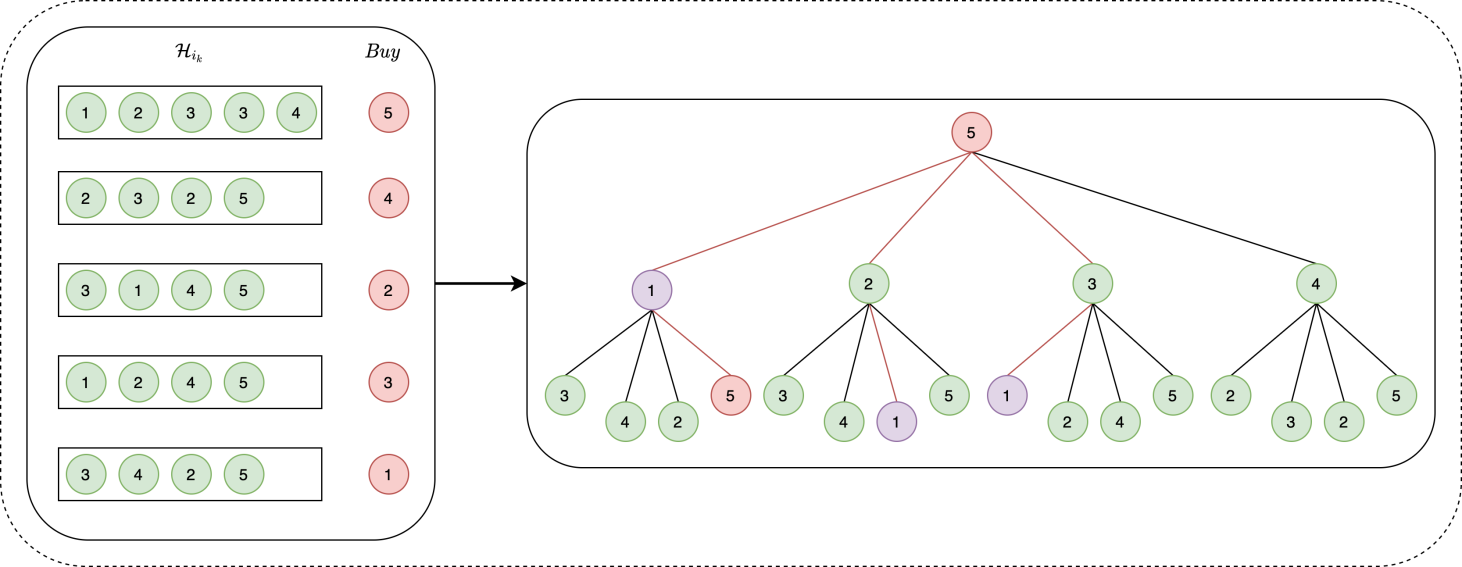
数据洞察
- 用户在本周在酒猜购买的酒店很大一部分都在购买前的前一个月点击过,按常理这些酒店应该具有一定的相似性。
- 用户在本周酒店点击之前的一段时间中点击的酒店之间应该也具有相似性。
酒猜用户活跃区间
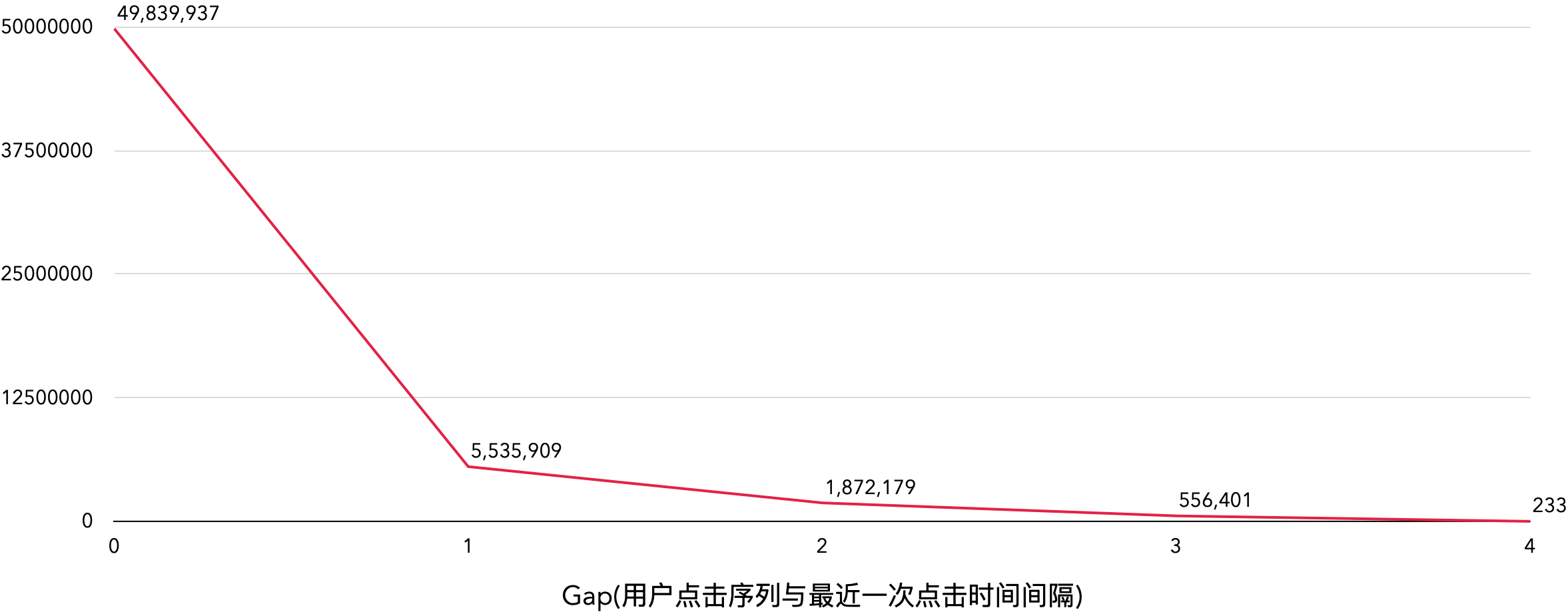
酒猜用户分位点&点击量图
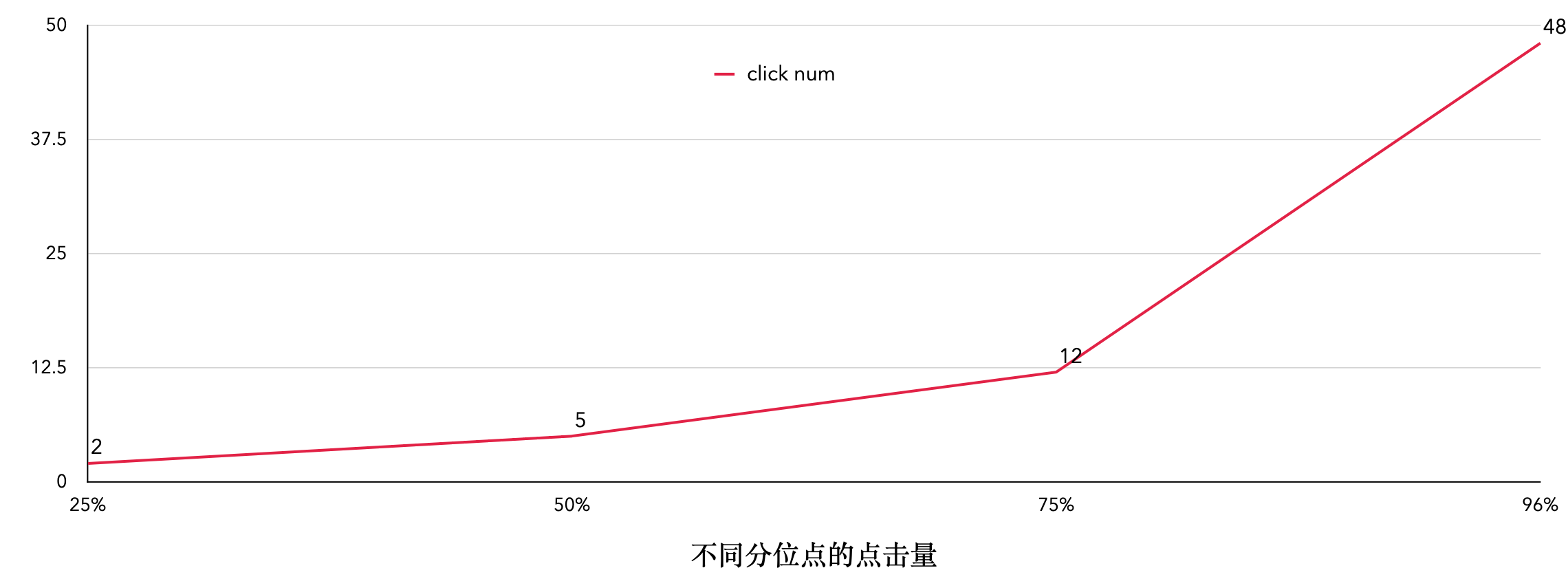
- 约96%的用户日点击次数在48次,后续实验为了保证时间性能,将click的次数限定在50次,这样就保证了能够满足绝大部分用户的习惯。
酒猜用户点击量分布图
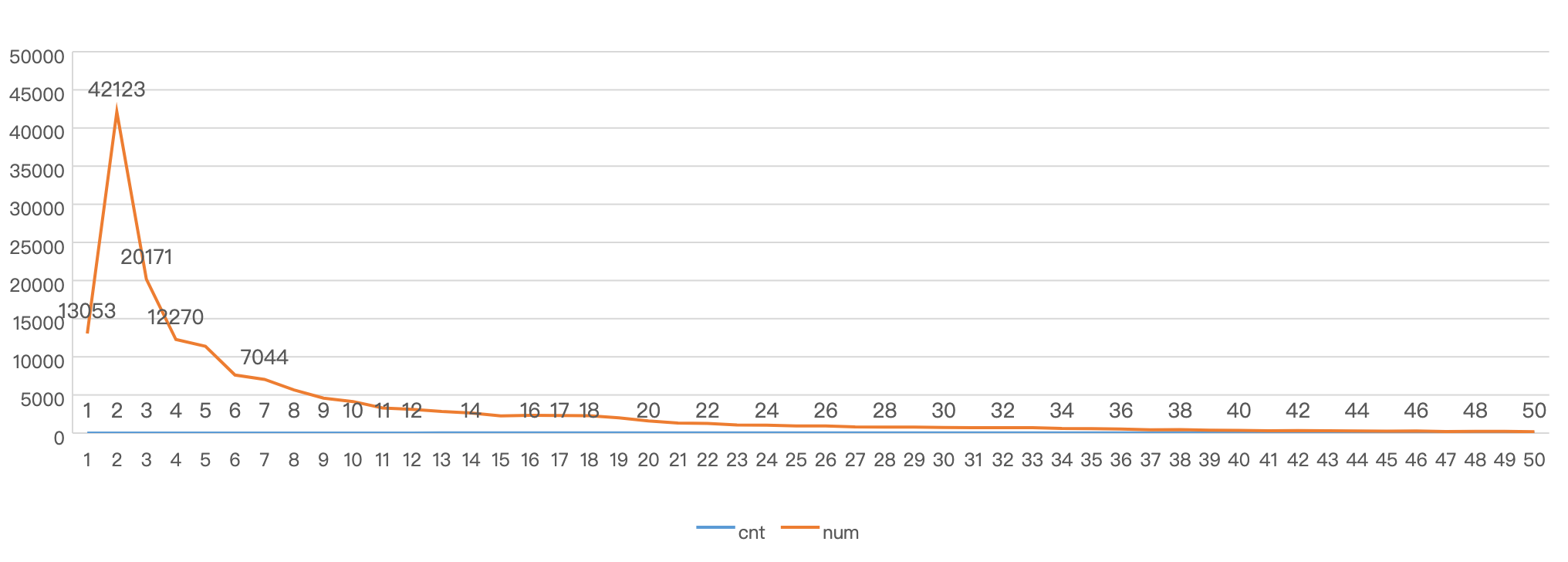
多叉树的直径分析
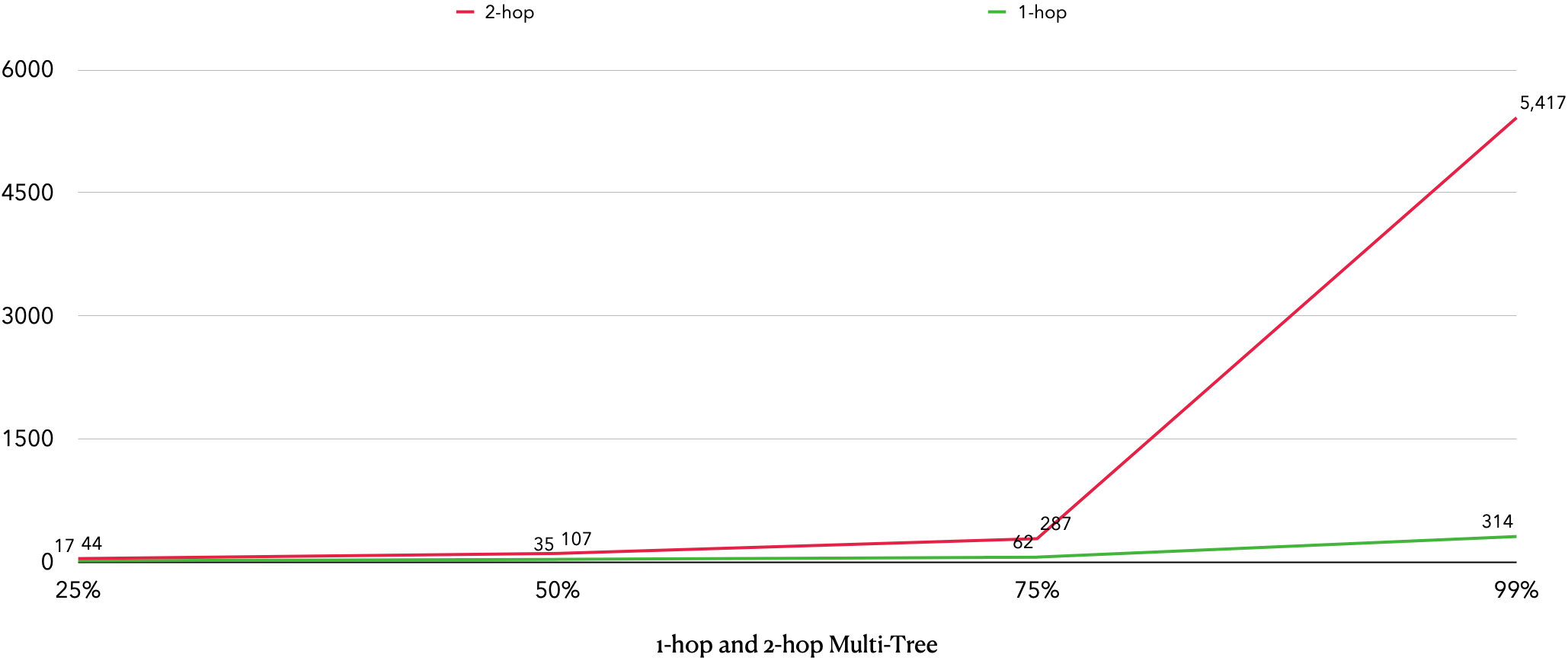
- 后期经试验,为了保证可行性与运算复杂度,1-hop采用500,2-hop采用10000
UDF实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| @annotate("string,string,string,string->double")
class simScore(object):
def evaluate(self,source_hotel,aim_hotel,one_hop,two_hop):
if source_hotel != None and aim_hotel != None and one_hop != None and two_hop != None:
score = 0.0
one_hop_hotels = one_hop.split(',')
two_hop_hotels = two_hop.split(',')
n1 = 0.0
n2 = 0.0
n3 = 0.0
for one_hop_hotel in one_hop_hotels:
if one_hop_hotel == aim_hotel:
n1+=1.0
for two_hop_hotel in two_hop_hotels:
if two_hop_hotel == source_hotel:
n2+=1.0
else:
for two_hop_hotel in two_hop_hotels:
if two_hop_hotel == aim_hotel:
n3+=1.0
score = 0.7 * n1/len(one_hop_hotels) + 0.7 * 0.3 * n2/len(two_hop_hotels) + 0.3 * 0.3 * n3/len(two_hop_hotels)
return score
else :
return 0.0
|
Result
online