NCL
Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning WWW 2022
概述
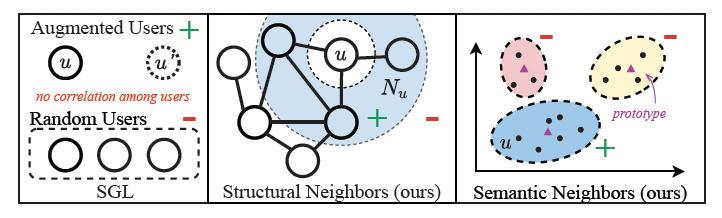 > 存在问题
> 存在问题
- 数据稀疏性
- 基于对比学习推荐算法的缺陷:
- 随机采样组合成为pair
- 未激发对比学习的潜力
解决方案
NCL模型的主要思想在于基于协同过滤的思想,采用GNN(图神经网络)提取用户侧以及商品侧的Embedding 。
- Graph Collaborative Filtering BackBone
- Contrastive Learning with Structural Neighbors
- Contrastive Learning with Semantic Neighbors
方案
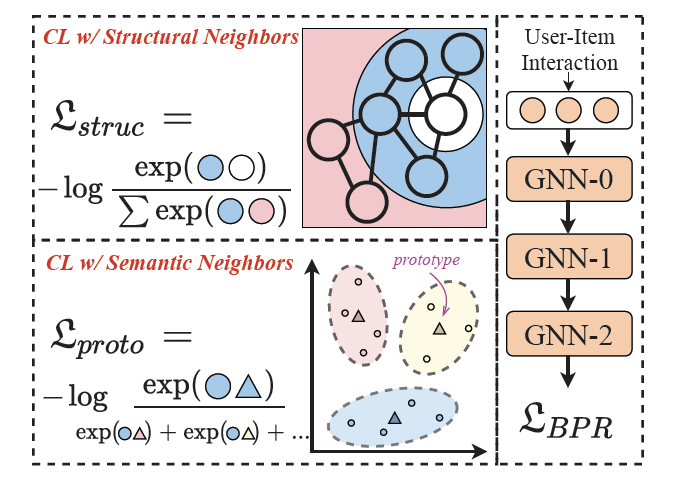 > Graph Collaborative Filtering BackBone
> Graph Collaborative Filtering BackBone
传统图协同过滤作为BackBone,采用BPR损失函数。
用户u与商品i的相似度可定义为(inner product):
经过L层GNN网络的用户表征为:
经过L层GNN网络的商品表征为:
Contrastive Learning with Structural Neighbors
结构邻居的对比学习,通过这种方式,我们可以从GNN模型的偶数层输出中获得同质邻居的表示。我们将同质邻域作为对比学习中的一对正样本,通过优化一下函数来达到基于结构邻居的对比学习策略.
用户侧的同质邻居的对比损失函数:
商品侧的同质邻居的对比损失函数:
总体的损失函数为:
Contrastive Learning with Semantic Neighbors
语义邻居的对比学习,在这种策略中,提出了原类型的概念,并提出了基于原类型的对比学习,此种思想认为结构对比损失平等地对待用户/商品的同质邻居,这不可避免地将噪声信息引入对比对。通过结合语义邻居来扩展对比对,语义邻居是指图上无法到达但具有相似特征(商品节点)或偏好(用户节点)的节点。
这部分通过聚类,将相似embedding对应的节点划分的相同的簇,用簇中心代表这个簇,这个中心称为原型。由于该过程无法进行端到端优化,使用 EM 算法学习提出的原型对比目标。聚类中GNN模型的目标是最大化(用户相关):
简单理解就是让用户embedding划分到某个簇,其中θ为可学习参数,R为交互矩阵,c是用户u的潜在原型。 用户侧的原型对比损失函数:
商品侧的原型对比损失函数:
总体的损失函数为:
最后,NCL模型的整体损失函数为: