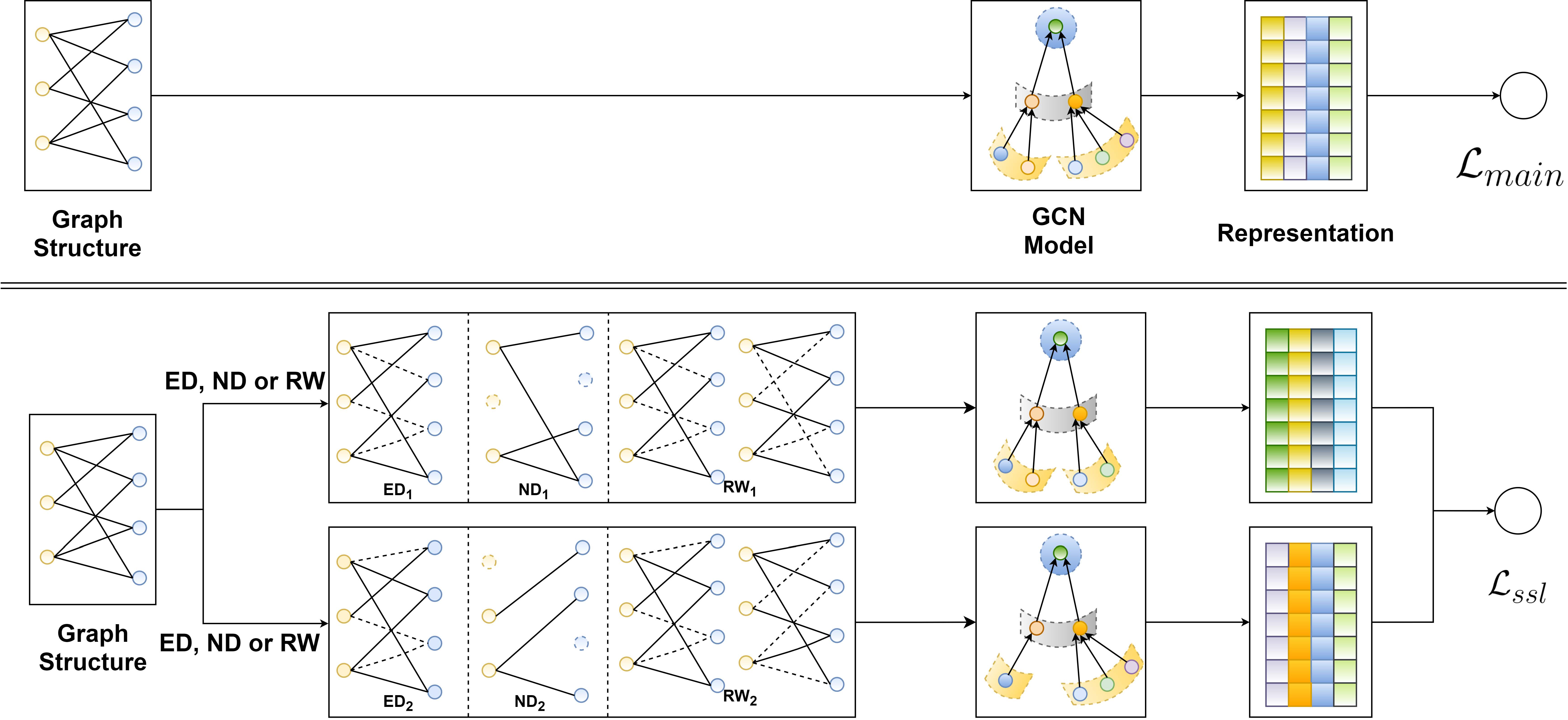
SGL
Wu, Jiancan, et al. "Self-supervised graph learning for recommendation." Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021.
概述
问题
- 推荐系统中存在严重的长尾分布
- 推荐系统中存在严重的噪声
- 推荐系统中数据非常稀疏
解决方案
- Data Augmentation
- ND(Node Dropout)
- ED(Edge Dropout)
- RW(Randow Walk)
- Contrastive Learning
- Multi-task Training
方案
类似于CV、NLP领域的数据增强操作,本篇论文主要设计了三种数据增强操作。这些数据操作可以被形式化的定义为:
其中
具体的数据增强操作下面进行详细阐述:
Data Augmentation on Graph Structure
Node Dropout
这种数据增强操作主要是通过按照一定的概率
其中,
这种数据增强操作主要是解决数据的结构敏感性。
Edge Dropout
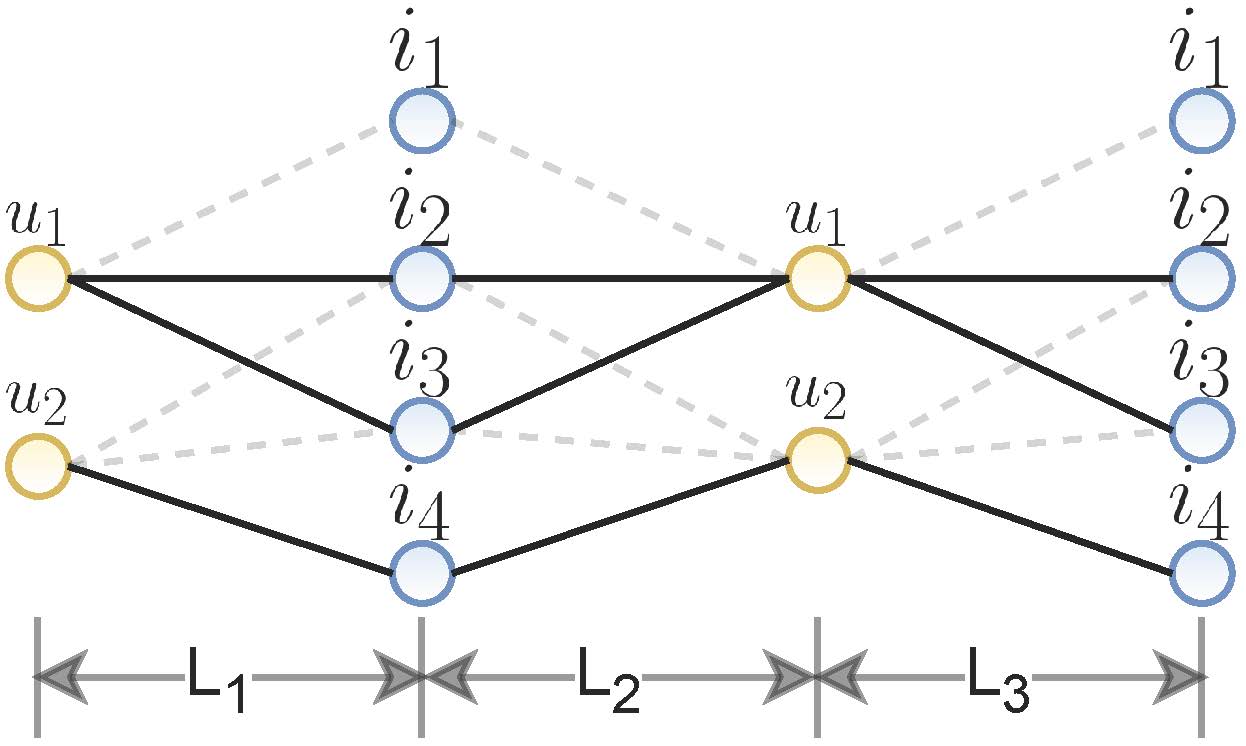 这种数据增强操作主要是通过按照一定的概率
这种数据增强操作主要是通过按照一定的概率
其中,
这种数据增强操作主要是解决噪声问题。
Random Walk
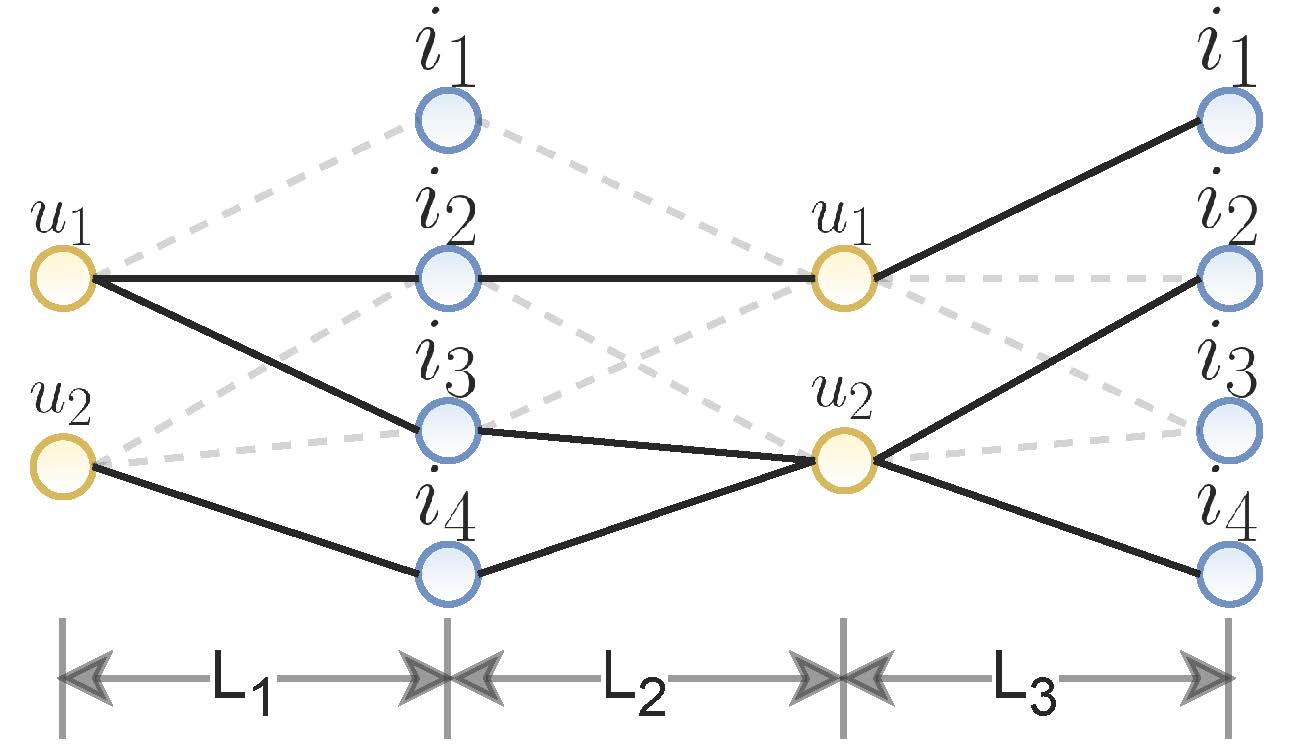 ) 这种数据增强操作与ED不同的是,此项数据增强操作可以获取高阶交互信息,主要发难是通过进行堆积ED layer的数据增强操作,针对于此种数据增强操作之后形成的两个子视图
) 这种数据增强操作与ED不同的是,此项数据增强操作可以获取高阶交互信息,主要发难是通过进行堆积ED layer的数据增强操作,针对于此种数据增强操作之后形成的两个子视图
其中,
这种数据增强操作主要是解决长尾问题(降低高频节点的出度)。
Contrastive Learning
基于对比学习的损失函数(item的损失函数类似):
总的损失函数:
Multi-task Training