SMRSL
Self-Supervised Multiple Representation Space Learning for Click-Through Rate Prediction
概述
Title:基于自监督的多表征联合优化CTR预估模型
目标
- 解决CTR任务中的数据稀疏性(Data Sparsity)与长尾现象(Long-tail Problem)
- 多任务学习框架中多个专家学习到的表征可能相同
- 多层次特征提取器中的样本表征存在纠缠
解决方案
Step1
首先利用一组子神经网络(a set of sub-networks)将一个单CTR任务转换成多CTR任务模型;
- 子神经网络(a set of sub-networks)目的在于学习一个潜在的语义空间,这样,那些比较稀疏、长尾分布中尾部的数据就会自动映射到某一个潜在的特征语义空间中。
Step2
设计两种自监督信号(self-supervision signals)去指导表征的学习。
- intra loss (intra-layer entanglement loss) :层内纠缠损失。(目的是为了鼓励每一个子神经网络去学习到不同的表示空间)
- inter loss (inter-layer structure loss) : 层间结构损失。(目的在于确保来自同一子神经网络的相邻编码网络的结构一致性)
方案
问题定义
给定有
一个CTR的模型目标是最小化损失函数
多表征空间的学习
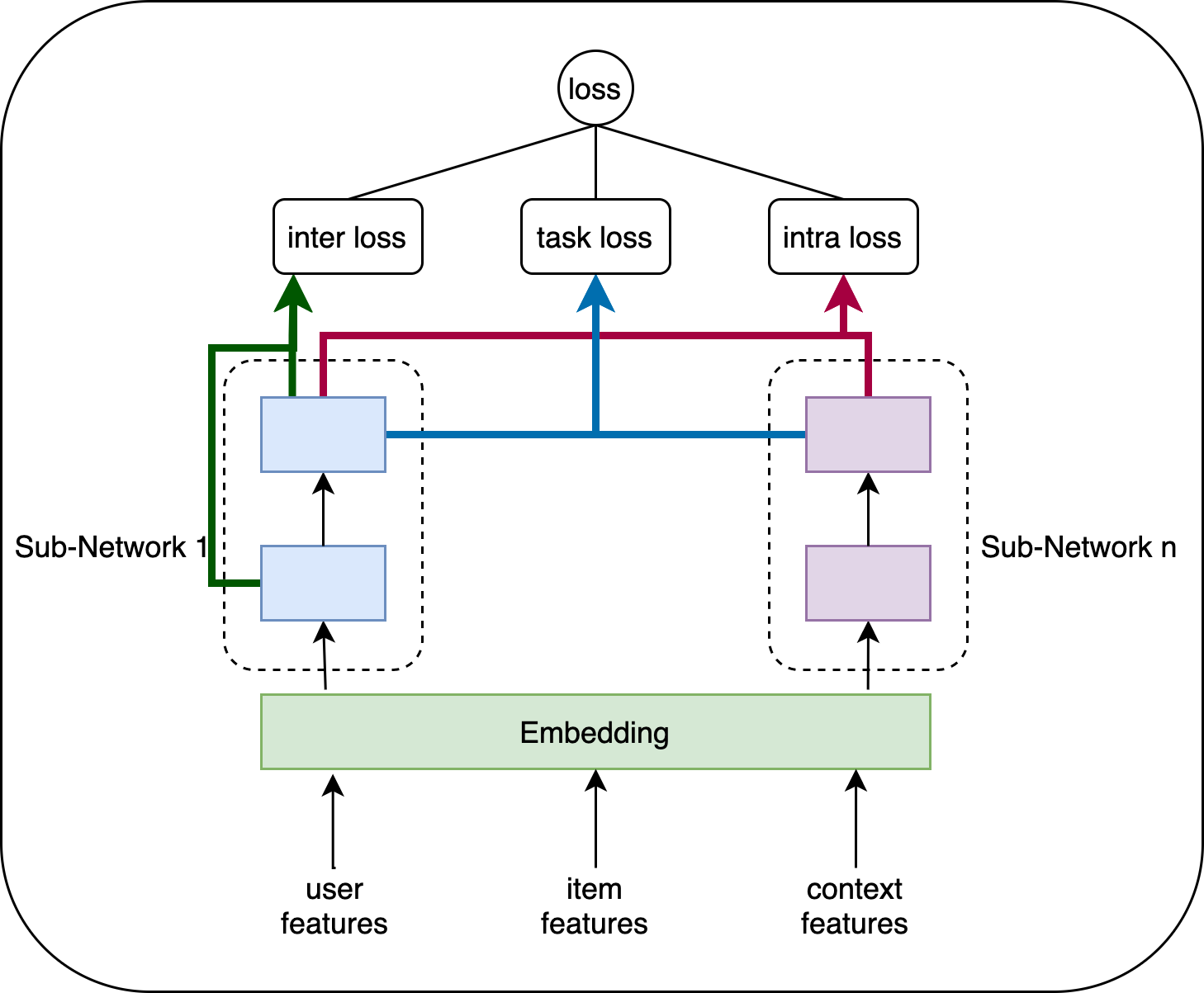
inter loss
以极端情况为例,在同一Sub-Network中,同一数据批次的最近邻索引应在两个相邻编码器层之间保持一致。
其中
其中
考虑到数据样本的不平衡性,一种基于权重的损失优化可以表示为:
其中
intra loss
其中,