AutoInt
Song, Weiping, et al. "Autoint: Automatic feature interaction learning via self-attentive neural networks." Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019.
概述
目标:
- 将原始高维(high-dimensional)、稀疏(sparse)的特征向量映射到低维(low-dimensional)空间中.
- 建模特征的高阶交互.
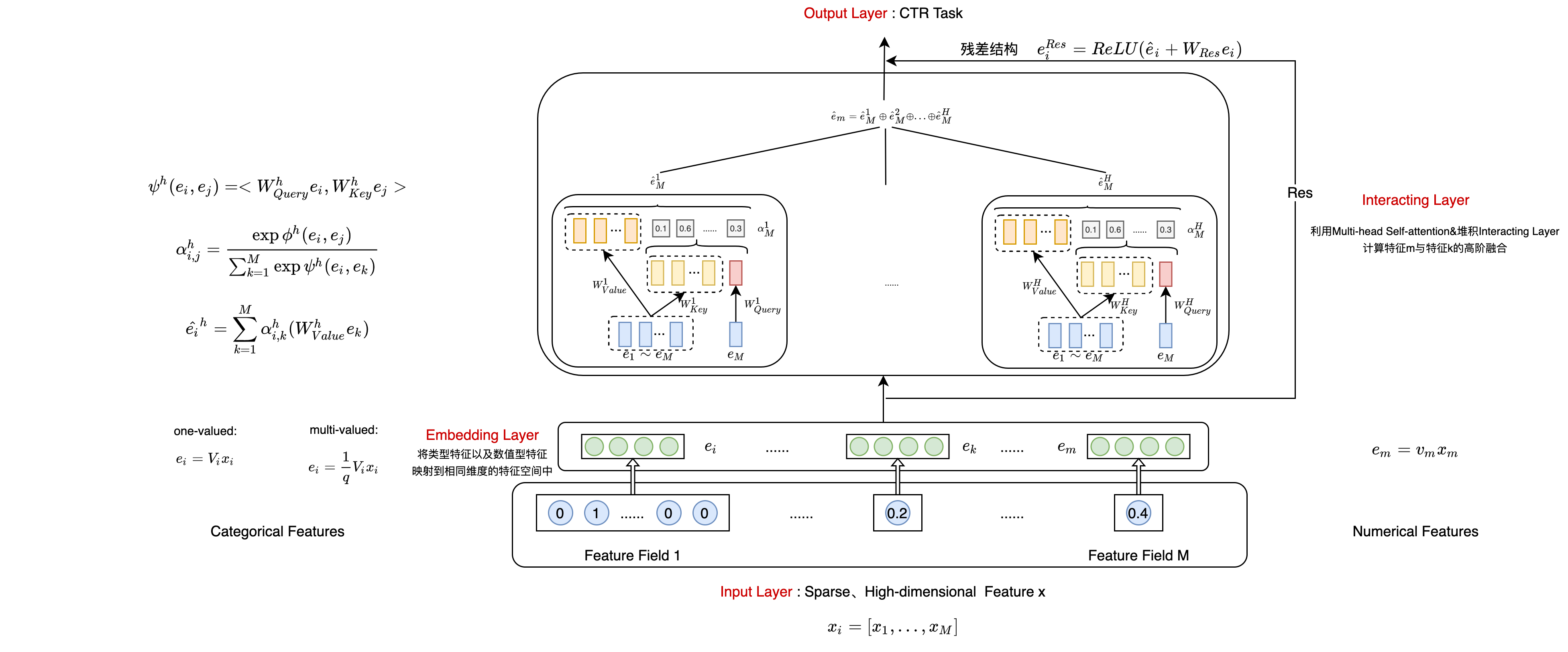 ## 方案 ### Input Layer
## 方案 ### Input Layer
在输入层,论文的方案是将用户侧的特征、商品侧的特征融合成为一个稀疏的表征向量。
Embedding Layer
总的目的就是将类别类型特征与数值类型特征映射到相同的维度空间(如:
类别类型特征:
one-value(e.g. movie company : marvel ) :
是one-hot向量(代表第 个特征域), 就是特征变换矩阵(embedding matrix)。 Multi-value(e.g. movie type : Romance;Drama etc.)
是one-hot向量(代表第 个特征域), 就是特征变换矩阵(embedding matrix), 是多值类型的值的数目。
数值类型特征:
经过Embedding Layer之后,所有特征域的特征向量都成为
Interacting Layer
交互层主要利用的是Multi-head的思想,这里以第
上述公式用来计算第
计算完相似度之后,利用上述公式计算第
最终得出第
其中,
通过一个Multi-head模块之后,得到的第
接下来,通过对
除此之外,还利用的残差结构防止过拟合,残差架构如下:
其中,
Output Layer
Training
最终采用交叉熵损失函数进行训练
整体而言,需要训练的参数有: